

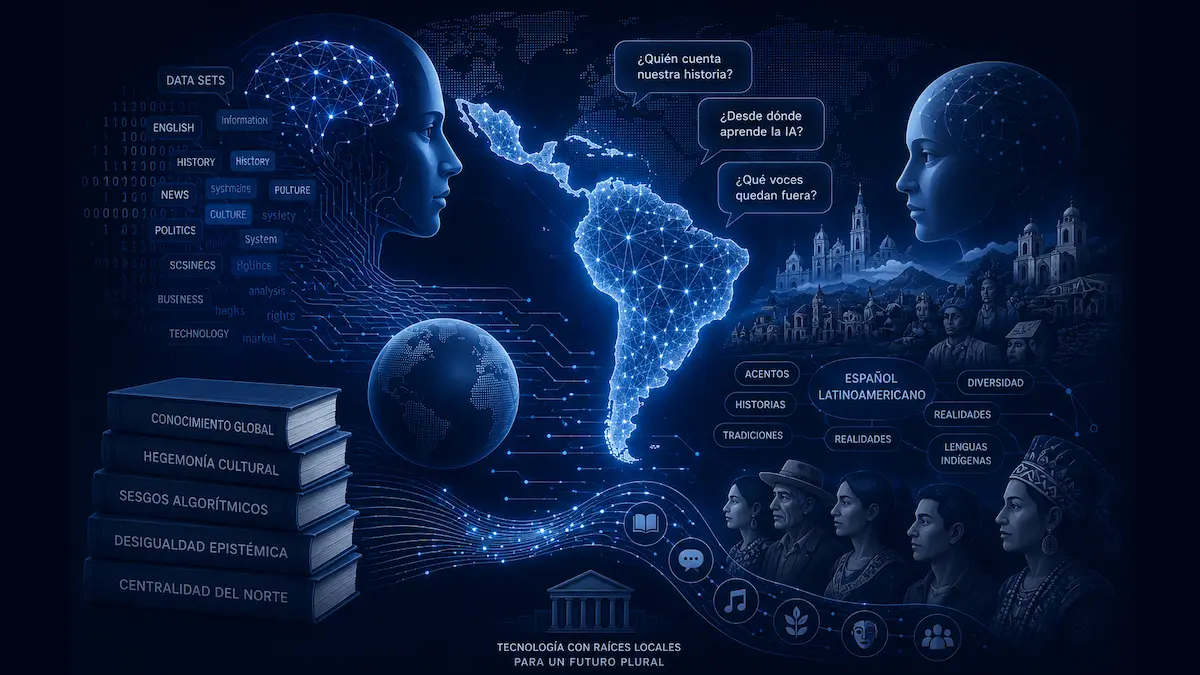
IA y América Latina: el sesgo invisible
La expansión acelerada de la inteligencia artificial ha abierto una discusión tecnológica, económica y filosófica de enorme importancia: ¿desde qué lugar del mundo están aprendiendo las máquinas? Aunque muchas veces se presenta a la IA como una herramienta universal y neutral, la realidad es que sus modelos de entrenamiento responden a geografías culturales muy específicas. Gran parte de las inteligencias artificiales dominantes fueron desarrolladas en Estados Unidos y entrenadas principalmente con datos en inglés. Esto ha provocado una situación peculiar: la IA puede hablar sobre América Latina, pero no necesariamente comprenderla desde dentro. En muchos casos, más que conocerla, la supone.
La afirmación puede sonar exagerada al principio. Después de todo, hoy existen sistemas capaces de escribir fluidamente en español, responder preguntas sobre historia latinoamericana o incluso generar textos que parecen cercanos culturalmente. Sin embargo, detrás de esa aparente familiaridad existe un problema estructural: la representación desigual del conocimiento en internet y en los grandes conjuntos de datos utilizados para entrenar modelos de IA.
La inteligencia artificial no “entiende” el mundo como lo hace una persona. No posee experiencia histórica ni conciencia cultural. Funciona detectando patrones estadísticos en enormes cantidades de información. Cuanto más aparece una idea, una palabra o una relación entre conceptos, más peso adquiere dentro del modelo. Por ello, si la mayor parte de los datos proviene del mundo anglosajón, las referencias culturales, sociales y políticas que la IA considera “normales” tienden a corresponder a ese entorno.
El problema no es únicamente lingüístico, sino epistemológico. La IA aprende una determinada visión del mundo. Aprende qué temas son relevantes, qué formas de narrar predominan, qué conceptos aparecen asociados entre sí y qué experiencias humanas reciben mayor atención digital. En ese contexto, América Latina muchas veces ocupa un lugar periférico.
IA en América Latina: cuando los datos hablan desde otros contextos
Esto se observa con claridad en el lenguaje cotidiano. El español latinoamericano posee una diversidad enorme de registros, acentos, referencias locales y formas de humor. No habla igual una persona de Monterrey que alguien de Bogotá, Lima o Buenos Aires. Sin embargo, muchas IAs producen un español artificialmente neutro, cercano al doblaje internacional o a textos corporativos globalizados. Aunque el resultado puede ser gramaticalmente correcto, a menudo pierde la textura cultural propia de las comunidades reales.
La situación se vuelve más compleja cuando se trata de temas históricos o sociales. Gran parte del contenido digital disponible sobre América Latina fue escrito desde perspectivas externas. Las narrativas internacionales suelen concentrarse en ciertos temas recurrentes: violencia, narcotráfico, migración, pobreza, inestabilidad política o exotización cultural. Como consecuencia, la IA puede terminar reproduciendo sesgos históricos no necesariamente por intención ideológica, sino porque esas asociaciones aparecen reiteradamente en los datos de entrenamiento. Es decir, la máquina no inventa el prejuicio; lo hereda estadísticamente.
Aquí aparece un fenómeno particularmente delicado: la diferencia entre hablar de una región y hablar desde una región. Una IA entrenada principalmente con documentos anglosajones puede ofrecer información sobre América Latina, pero muchas veces carece de la densidad cultural que surge de las experiencias locales. Puede reconocer hechos históricos, mencionar tradiciones o explicar procesos políticos, pero no necesariamente comprender las resonancias simbólicas que tienen para quienes viven esos contextos.
La situación recuerda, en cierto modo, viejas formas de centralismo cultural. Durante siglos, muchas regiones del mundo fueron interpretadas desde centros de poder externos que producían el conocimiento legítimo sobre ellas. Hoy, algo similar puede ocurrir con los sistemas algorítmicos: los países que poseen mayor capacidad tecnológica y mayor producción digital terminan definiendo gran parte de las categorías con las que la IA organiza el mundo.
Sesgos culturales y representación desigual del conocimiento
Esto no significa que exista una conspiración deliberada contra América Latina. El problema es más estructural que intencional. Las grandes empresas tecnológicas entrenan sus modelos con los datos más abundantes y accesibles disponibles en internet. Y la producción digital global sigue profundamente desequilibrada. El inglés domina la investigación científica, la documentación técnica, los foros especializados y buena parte de los archivos digitalizados utilizados por las compañías de IA.
Además, existe otro obstáculo importante: muchas experiencias latinoamericanas simplemente no están suficientemente documentadas en formato digital. Una enorme cantidad de conocimiento local permanece fuera de las bases de datos que alimentan a las inteligencias artificiales. Tradiciones orales, investigaciones regionales, producción académica de circulación limitada, literatura local, lenguas indígenas y dinámicas comunitarias quedan subrepresentadas frente al volumen masivo de información proveniente de otras regiones.
Aun así, sería incorrecto afirmar que la IA desconoce completamente América Latina. En los últimos años el contenido en español ha crecido de manera exponencial. Universidades, medios digitales, creadores de contenido y centros de investigación latinoamericanos participan cada vez más en la construcción del ecosistema digital. Los modelos actuales manejan mucho mejor el español que generaciones anteriores y son capaces de adaptarse con mayor flexibilidad a contextos regionales.
IA en América Latina: más allá del idioma, la cuestión cultural
Sin embargo, persiste una diferencia fundamental entre capacidad lingüística y comprensión cultural. Una IA puede aprender a redactar correctamente en español sin captar plenamente los códigos sociales, las tensiones históricas y las sensibilidades específicas de la región. Puede utilizar palabras latinoamericanas, pero seguir organizando su visión del mundo desde parámetros externos.
Por ello, la discusión sobre inteligencia artificial en América Latina no debería limitarse al consumo tecnológico. La pregunta central es otra: ¿quién construirá las inteligencias artificiales del futuro y desde qué horizonte cultural lo hará?
En este punto, el papel de las compañías latinoamericanas se vuelve decisivo. Si la región depende exclusivamente de modelos entrenados fuera de sus contextos históricos y lingüísticos, corre el riesgo de convertirse únicamente en usuaria de tecnologías diseñadas desde otras realidades. Eso implicaría aceptar no solo herramientas externas, sino también marcos culturales ajenos incorporados en los sistemas algorítmicos.
México posee condiciones especialmente importantes para participar en este proceso. Su tamaño poblacional, su producción cultural, su infraestructura universitaria y su creciente ecosistema tecnológico podrían convertirlo en uno de los principales centros latinoamericanos de desarrollo de IA. Pero para ello no basta con utilizar herramientas existentes; es necesario crear modelos propios, entrenados con datos regionales y sensibles a las realidades locales.
Soberanía tecnológica y construcción de modelos regionales
Desarrollar inteligencia artificial desde América Latina permitiría algo más profundo que mejorar modismos o adaptar asistentes virtuales. Significaría incorporar otras formas de narrar el mundo, otras prioridades sociales y otras experiencias históricas dentro de los sistemas tecnológicos del futuro. También abriría oportunidades económicas estratégicas en un campo que probablemente definirá buena parte de la economía global durante las próximas décadas.
La IA no es únicamente una tecnología; también es una forma de organizar el conocimiento. Por eso resulta tan importante que América Latina deje de ser solo un objeto descrito por algoritmos externos y comience a participar activamente en la construcción de esas inteligencias. De lo contrario, las máquinas seguirán hablando de la región desde una distancia estadística que muchas veces confunde representación con comprensión. El desafío, entonces, no consiste únicamente en que la IA aprenda español. El verdadero reto es que aprenda América Latina desde América Latina.
Para saber más...
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021)
On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?
Proceedings of FAccT 2021
https://dl.acm.org/doi/10.1145/3442188.3445922 - Blodgett, S. L., Barocas, S., Daumé III, H., & Wallach, H. (2020)
Language (Technology) is Power: A Critical Survey of “Bias” in NLP
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)
https://aclanthology.org/2020.acl-main.485/ - Birhane, A., Prabhu, V. U., Kahembwe, E., & Njoroge, J. (2024)
AI Auditing: The Broken Bus on the Road to AI Accountability
https://dl.acm.org/doi/10.1145/3630106.3658544
SIU
La Unidad de Inteligencia e Interpretación (SIU) de Celestial Dynamics transforma datos en estrategias accionables mediante análisis avanzado, estudios de mercado y evaluación de tendencias en IA y HPC. Su misión es proporcionar insights clave para la toma de decisiones en negocios, políticas públicas y transformación digital, optimizando el impacto de la tecnología en múltiples sectores.
You May Also Like


La “habitación china” y el debate sobre la inteligencia artificial
Hace más de cuarenta años, cuando las computadoras apenas comenzaban a formar parte de la vida cot
Grafos: pensar el conocimiento como una red
Los grafos permiten representar personas, organizaciones, conceptos y eventos mediante redes de rela